publications
Deep Learning, Computer Vision, Diffusion, Image Synthesis, AIGC.
2025
- CVIU
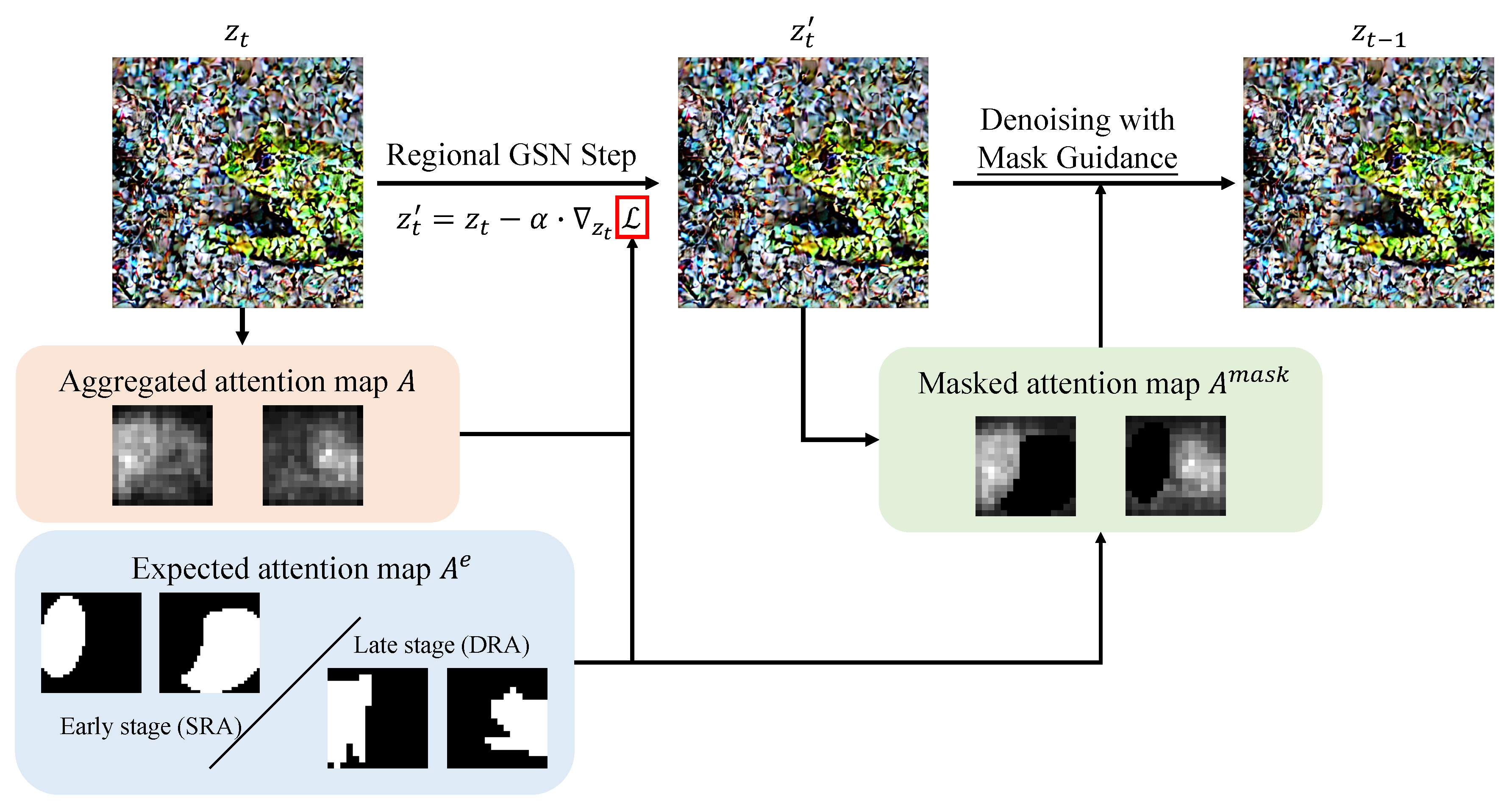 Comprehensive regional guidance for attention map semantics in text-to-image diffusion modelsHaoxuan Wu, Lai-Man Po, Xuyuan Xu, Kun Li, Yuyang Liu, and 1 more authorComputer Vision and Image Understanding, 2025
Comprehensive regional guidance for attention map semantics in text-to-image diffusion modelsHaoxuan Wu, Lai-Man Po, Xuyuan Xu, Kun Li, Yuyang Liu, and 1 more authorComputer Vision and Image Understanding, 2025Diffusion models have shown remarkable success in image generation tasks. However, accurately interpreting and translating the semantic meaning of input text into coherent visuals remains a significant challenge. We observe that existing approaches often rely on enhancing attention maps in a pixel-based or patch-based manner, which can lead to issues such as non-contiguous regions, unintended region leakage, eventually causing attention maps with limited semantic richness, degrade output quality. To address these limitations, we propose CoRe Diffusion, a novel method that provides comprehensive regional guidance throughout the generation process. Our approach introduces a region-assignment mechanism coupled with a tailored optimization strategy, enabling attention maps to better capture and express semantic information of concepts. Additionally, we incorporate mask guidance during the denoising steps to mitigate region leakage. Through extensive comparisons with state-of-the-art methods and detailed visual analyses, we demonstrate that our approach achieves superior performance, offering a more faithful image generation framework with semantically accurate procedure. Furthermore, our framework offers flexibility by supporting both automatic region assignment and user-defined spatial inputs as conditional guidance, enhancing its adaptability for diverse applications.
- ESWARMP-adapter: A region-based Multiple Prompt Adapter for multi-concept customization in text-to-image diffusion modelExpert Systems with Applications, 2025
This paper introduces a novel framework for multi-concept customization in text-to-image diffusion models. At its core is a Multiple Prompt Adapter (MP-Adapter) capable of processing multiple image prompts in parallel, extracting features from target concepts and projecting them into the same latent space as the text prompt. This enables simultaneous handling of multiple concepts using just one reference image per concept. To address challenges in fusing multiple concepts with complex interactions, we propose a Region-based Denoising Framework (RDF) that dynamically generates concept-specific regions of interest during inference, allowing spatially decoupled injection of concept features. By integrating the MP-Adapter and RDF, our end-to-end pipeline enables multi-concept customization with intricate occlusions and interactions while preserving concept identities. This approach surpasses current methods by resolving concept conflicts, identity degradation, and occlusion issues, allowing flexible customization without concept-specific retraining. Both qualitative and quantitative evaluations demonstrate that our framework outperforms state-of-the-art approaches in multi-concept customization tasks, while ablation studies validate the effectiveness of each proposed component. This work significantly advances text-to-image generation capabilities for complex, user-defined concept combinations. Code and models will be released at https://github.com/baojudezeze/RMP-Adapter.
- MMS
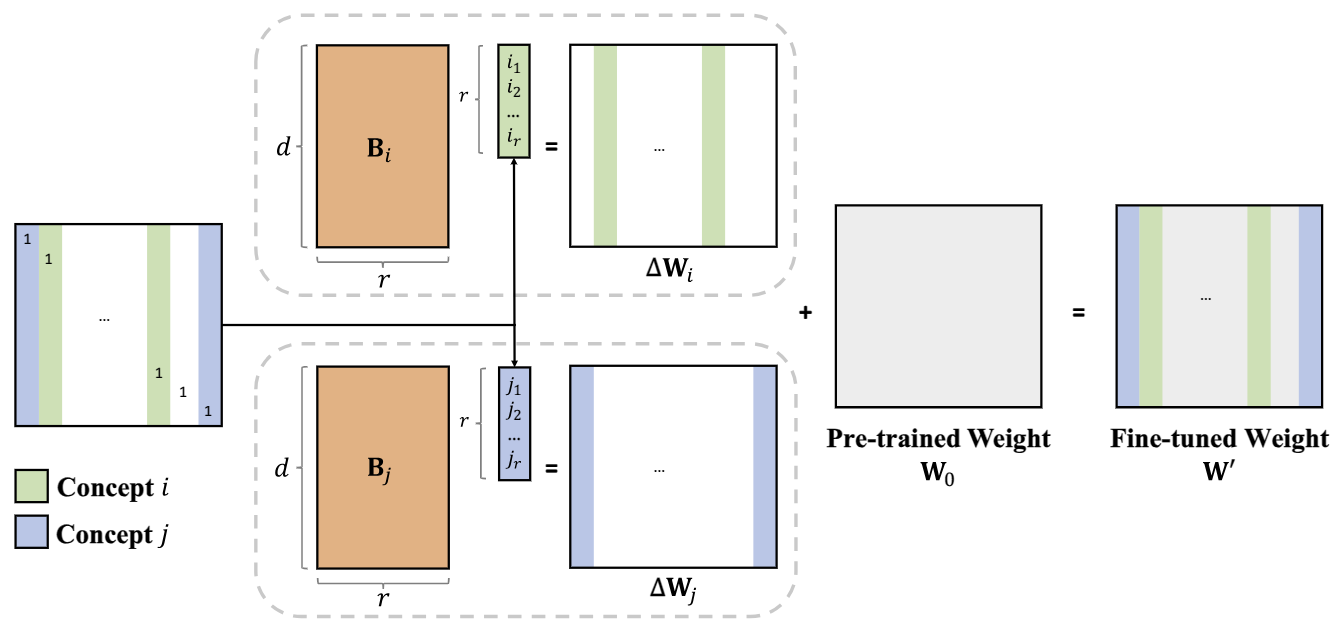 Multi-SBoRA: regional and non-overlapping weight updates for multi-concept customization of diffusion modelsMultimedia Systems, Oct 2025
Multi-SBoRA: regional and non-overlapping weight updates for multi-concept customization of diffusion modelsMultimedia Systems, Oct 2025Customizing diffusion models for multiple concepts remains challenging due to cross-concept interference. This paper introduces Multi-SBoRA, a novel method for customizing diffusion models for multiple concepts. By leveraging orthogonal standard basis vectors, Multi-SBoRA constructs low-rank matrices for LoRA fine-tuning, enabling regional and non-overlapping weight updates that effectively mitigate crosstalk between different concepts. This approach preserves the knowledge embedded in the pre-trained model and reduces interference between customized concepts, thereby ensuring that each concept is learned independently without compromising its integrity. The localized weight updates also reduce computational overhead and enhance model flexibility. Experimental results demonstrate the optimal quantitative performance of Multi-SBoRA, showcasing its efficacy in addressing multi-concept customization while maintaining independence via orthogonality and localized updates, and mitigating crosstalk effects.
2024
- TCSVTSelf-Calibration Flow Guided Denoising Diffusion Model for Human Pose TransferIEEE Transactions on Circuits and Systems for Video Technology, Oct 2024
The human pose transfer task aims to generate synthetic person images that preserve the style of reference images while accurately aligning them with the desired target pose. However, existing methods based on generative adversarial networks (GANs) struggle to produce realistic details and often face spatial misalignment issues. On the other hand, methods relying on denoising diffusion models require a large number of model parameters, resulting in slower convergence rates. To address these challenges, we propose a self-calibration flow-guided module (SCFM) to establish precise spatial correspondence between reference images and target poses. This module facilitates the denoising diffusion model in predicting the noise at each denoising step more effectively. Additionally, we introduce a multi-scale feature fusing module (MSFF) that enhances the denoising U-Net architecture through a cross-attention mechanism, achieving better performance with a reduced parameter count. Our proposed model outperforms state-of-the-art methods on the DeepFashion and Market-1501 datasets in terms of both the quantity and quality of the synthesized images. Our code is publicly available at https://github.com/zylwithxy/SCFM-guided-DDPM.
- ICONIPSBoRA: Low-Rank Adaptation with Regional Weight UpdatesarXiv preprint arXiv:2407.05413, Oct 2024
This paper introduces Standard Basis LoRA (SBoRA), a novel parameter-efficient fine-tuning approach for Large Language Models that builds upon the pioneering works of Low-Rank Adaptation (LoRA) and Orthogonal Adaptation. SBoRA reduces the number of trainable parameters by half or doubles the rank with the similar number of trainable parameters as LoRA, while improving learning performance. By utilizing orthogonal standard basis vectors to initialize one of the low-rank matrices (either A or B), SBoRA facilitates regional weight updates and memory-efficient fine-tuning. This results in two variants, SBoRA-FA and SBoRA-FB, where only one of the matrices is updated, leading to a sparse update matrix ΔW with predominantly zero rows or columns. Consequently, most of the fine-tuned model’s weights (W0+ΔW) remain unchanged from the pre-trained weights, akin to the modular organization of the human brain, which efficiently adapts to new tasks. Our empirical results demonstrate the superiority of SBoRA-FA over LoRA in various fine-tuning tasks, including commonsense reasoning and arithmetic reasoning. Furthermore, we evaluate the effectiveness of QSBoRA on quantized LLaMA models of varying scales, highlighting its potential for efficient adaptation to new tasks. Code is available at this https URL